Kana App
Vai all'appUn'app costruita con React per ripassare i due sillabari della lingua giapponese: hiragana e katakana.
Ho voluto creare questa app per aggiungere al mio sito Hanami Blog una funzione utile a chi si sta approcciando allo studio del giapponese.
In realtà esistono altri siti con lo stesso scopo, ma ciò che rende diversa quest'app è la possibilità di ripassare i caratteri all'interno di parole giapponesi. Per fare un paragone con l'italiano, è come esercitarsi a leggere le lettere dell'alfabeto dentro le parole.
Come funziona
L'applicazione è composta da 4 diverse fasi, descritte dalle immagini successive.
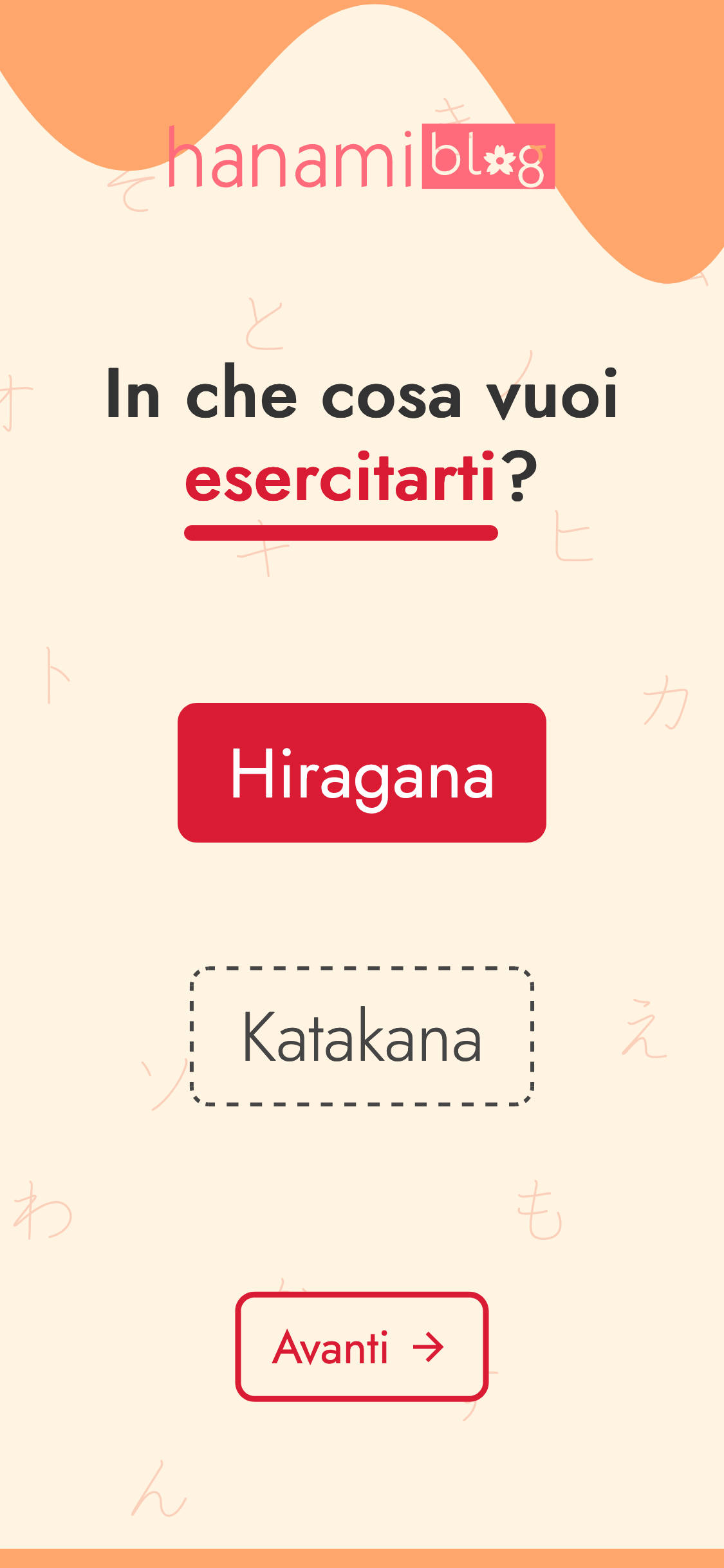

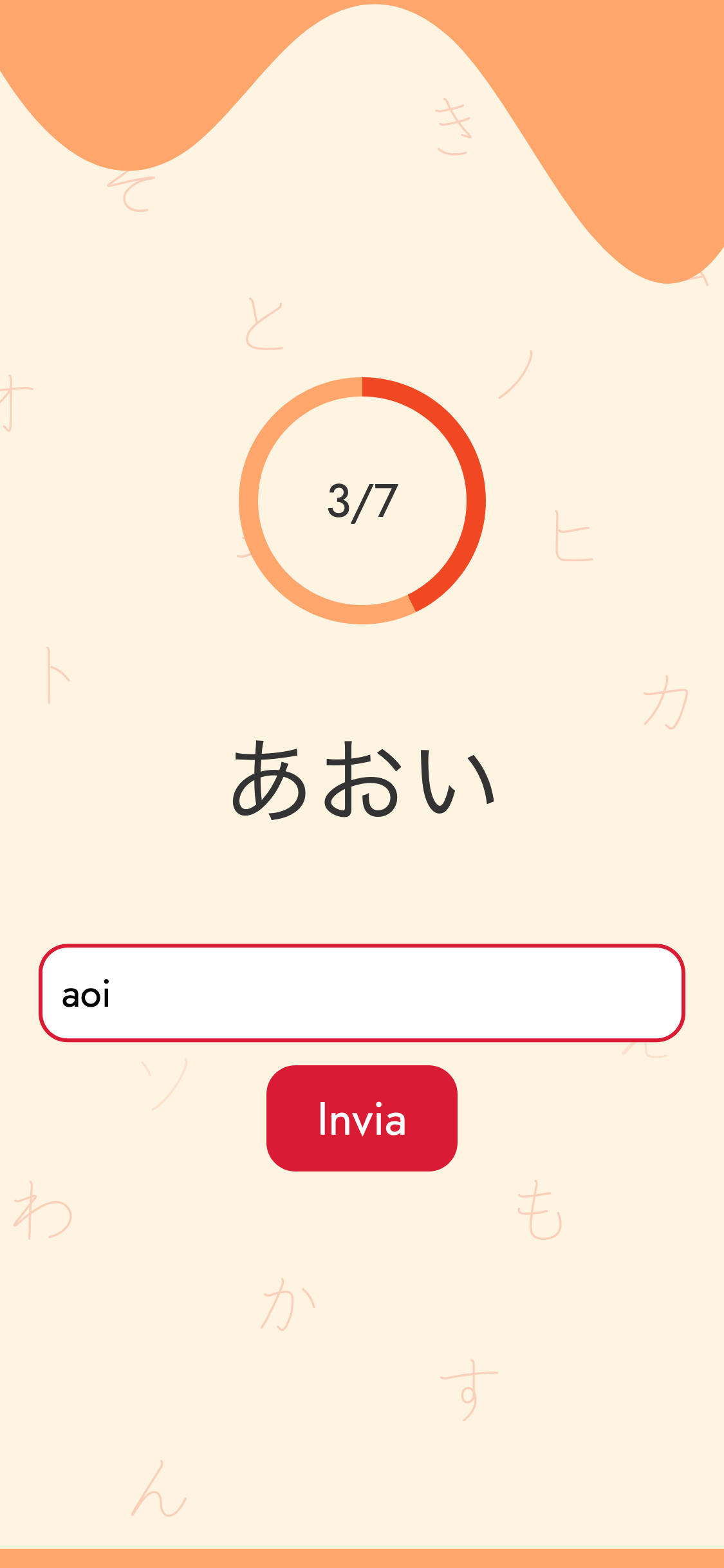
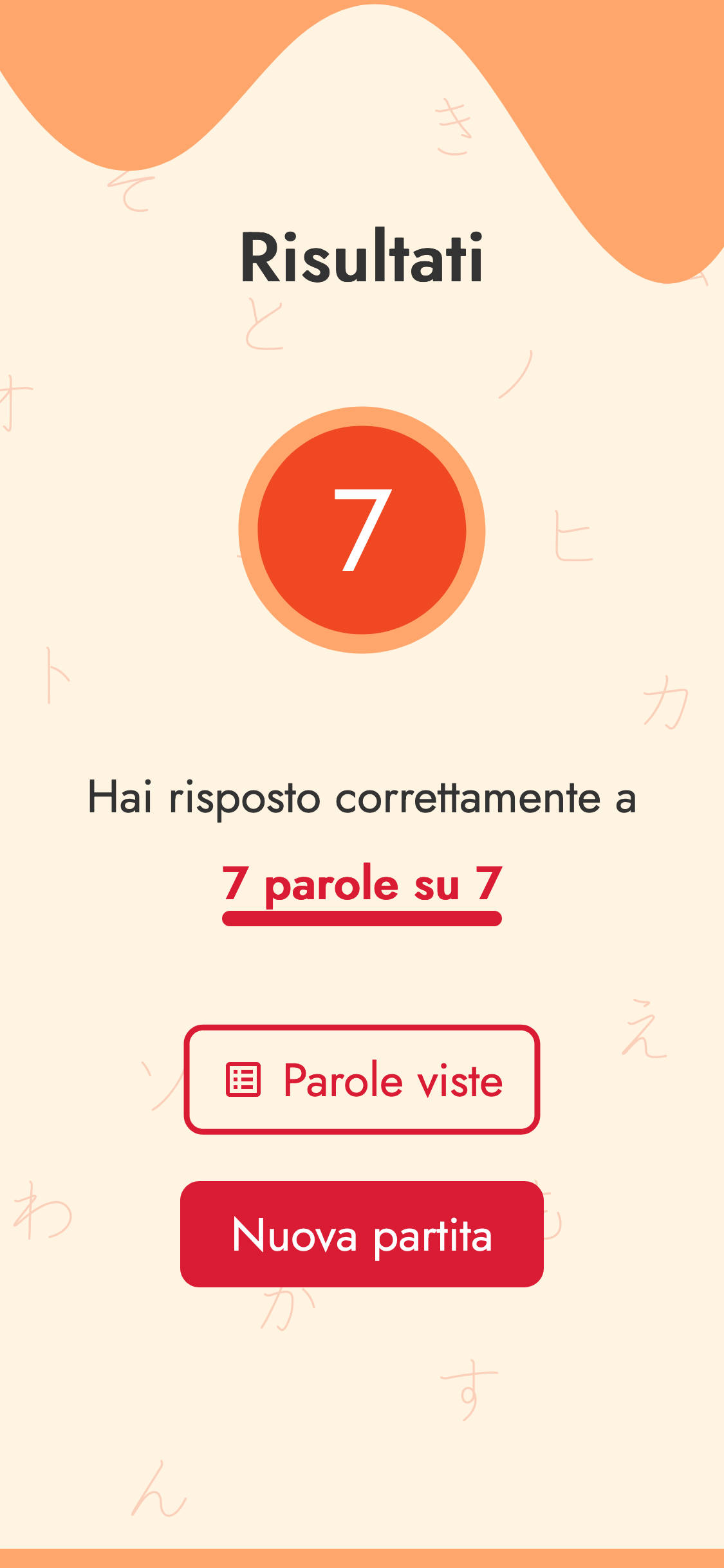

Grafica e UI
Essendo parte del sito principale, ho cercato di rendere l'app simile al sito usando gli stessi colori. Per distinguerla dal sito ho aggiunto un leggero sfondo con caratteri giapponesi e il motivo di un'onda in cima.
Inizialmente avevo pensato di raggruppare in una sola pagina sia la scelta del sillabario che le altre impostazioni. Infine ho scelto di separare in due fasi per evitare di dare troppe opzioni in una sola pagina e per far comprendere che si può ripassare un solo sillabario alla volta.
Dettagli tecnici
Ho scelto di costruire l'app in un'unica pagina per evitare il caricamento da parte dell'utente di una pagina diversa del percorso previsto. Il cambiamento di ogni pagina è gestito da un unico stato che viene cambiato al click di determinati bottoni.
La funzione che caratterizza l'app è senza dubbio quella che si occupa di scegliere le parole da mostrare all'utente in maniera casuale a seconda delle opzioni inserite.
Quando l'utente sceglie determinati caratteri, l'app mostra parole che contengono solamente quei caratteri scelti. Il modo più semplice per determinare se una certa parola contiene o meno certi caratteri è ricercare le singole sillabe all'interno di un array. Per questo ho scelto di trascrivere ciascuna parola giapponese in lettere suddividendo ciascuna sillaba in un array (la proprietà "romaji" dell'esempio sottostante).
const hiraganaWords = [{ kana: "あか", romaji: ["a","ka"], kanji: "赤" },
//...
]Le sillabe selezionate dall'utente vengono memorizzate in un array di uno stato, il cui stato iniziale ha al suo interno suoni che possono trovarsi all'interno delle parole e non sono specifici della selezione (allungamenti di vocale, consonanti doppie). Questi suoni iniziali sono preceduti da un trattino in modo tale da distinguerli dagli altri selezionabili.
Una volta selezionare le sillabe l'app sceglie prima tutte parole che contengono soltanto quelle sillabe tramite i metodi filter e every, dopodiché viene svolta una selezione casuale scegliendo un numero massimo di parole determinato dall'utente.
//funzione che seleziona parole in modo casuale
function selectWordsRandom(filteredWords) {
const selectedWordsSet = new Set();
if (filteredWords.length > maxNumberOfWords) {
while (selectedWordsSet.size < maxNumberOfWords) {
const randomIndex = Math.floor(Math.random() * filteredWords.length);
selectedWordsSet.add(filteredWords[randomIndex]);
}
setSelectedWords([...selectedWordsSet]);
} else {
//se le parole disponibili sono meno dell'opzione scelta dall'utente mescola l'array
shuffle(filteredWords);
setMaxNumberOfWords(filteredWords.length);
setSelectedWords(filteredWords);
}
}
// funzione per determinare l'array di parole con determinate sillabe
function setArrayOfWords() {
const array = isHiragana ? hiraganaWords : katakanaWords;
if (selectedKana.length === (totalKana.length + initialSounds.length)) {
return array;
} else {
return array.filter(word => word.romaji.every((letter) => {
return selectedKana.indexOf(letter) !== -1;
}))
}
}Vedi il codice completo su Github
Cosa ho imparato da questo progetto
Da questo progetto ho imparato principalmente a:
- gestire gli stati e gli effetti in React
- strutturare meglio il codice
- trovare una soluzione per la funzione principale dell'app